BuildingBlocks
Brief description of the submodule
In this submodule all of the classes used to build the neural networks are presented. The resulting networks built can be found in the U_Net module.
DoubleConv
Class containing the double convolutions performed on the U-Net architecture.
The class inherits the attributes and methods of torch.nn.Module.
Every convolution block consists of:
- A 2D convolution layer with
- kernel size: 3x3
- padding: 1
- bias: False
- A batch normalization layer
- A ReLU activation function
Moreover, an option to include residual connections in the double convolutions is available by using the attribute resunet = True.
Attributes
-
self.in_channels: (int) Number of channels that the module receives.
-
self.out_channels: (int) Number of channels that will be obtained with the two convolutions performed.
-
self.mid_channels: (int) If specified, this will be the number of channels calculated by the first convolution. Default is None.
-
self.resunet: (Boolean) Boolean used to indicate if the double convolution will have a residual connection or not. Default is False.
-
self.double_conv (torch.nn.Sequential) Sequential layer comprising the convolutions, batch normalizations and ReLU activation functions.
-
self.shortcut: (torch.nn.Conv2d) PyTorch layer with one 2D convolution which will be used as the identity mapping for the residual connection if the
self.resunet = True.- kernel size: 1
- padding: 0
- stride: 1
Methods
- forward: Function to perform the forward step of the group of PyTorch layers.
Source code
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None, resunet = False):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.mid_channels = mid_channels
self.resunet = resunet
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
if resunet:
# Identity mapping
self.shortcut = nn.Conv2d(in_channels, out_channels, kernel_size = 1, padding = 0, stride = 1, bias = False)
def forward(self, x):
y = self.double_conv(x)
if self.resunet:
s = self.shortcut(x)
y = y + s
return y
Down
Class containing the downsampling steps used on the contracting path of the UNet architecture. The downscaling is performed using MaxPooling method with a value of pooling = 2
After downsampling with maxpool, a Double Convolution is applied in the lower resolution.
It inherits the attributes and methods of torch.nn.Module.
Attributes
-
self.in_channels: (int) Number of channels that the module receives.
-
self.out_channels: (int) Number of channels that will be obtained with the two convolutions performed.
-
self.resunet: (Boolean) Boolean used to indicate if the double convolution will have a residual connection or not. Default is False.
-
self.maxpool_conv: (torch.nn.Sequential) Sequential layer comprising the 2D maxpooling and the posterior double convolutions performed.
Methods
- forward: Function to perform the forward step of the group of PyTorch layers.
Source code
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels, resunet = False):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.resunet = resunet
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels, resunet = resunet)
)
def forward(self, x):
return self.maxpool_conv(x)
Up
Class containing the upsampling steps performed on the expanding path of the UNet architecture.
The upsampling can be performed either using bilinear interpolation or transpose convolutions. After the upsampling is done, the feature map of the same level in the contracting path is concatenated and then a Double convolution is performed.
Moreover, an option of including attention gates is possible using the attribute self.attention = True.
This class inherits the attributes and methods of torch.nn.Module.
Attributes
- self.in_channels: (int) Number of channels that the module receives.
- self.out_channels: (int) Number of channels that will be obtained with the two convolutions performed.
- self.bilinear: (Boolean) Boolean to indicate if the upsampling method will be either bilinear interpolation or transpose 2D convolutions. Default is False.
- self.attention: (Boolean) Boolean to indicate if attention gates will be added on the upsampling step. Default is False.
- self.resunet: (Boolean) Boolean used to indicate if the double convolution will have a residual connection or not. Default is False.
Methods
- forward: Function to perform the forward step of the group of PyTorch layers.
Source code
class Up(nn.Module):
"""Upsampling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True, attention = False, resunet = False):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.resunet = resunet
self.bilinear = bilinear
self.attention = attention
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2, resunet = resunet)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels, resunet = resunet)
if attention:
self.attn = Attention_block(in_channels//2, in_channels//2, in_channels//4)
def forward(self, x1, x2):
a1 = self.up(x1)
diffY = x2.size()[2] - a1.size()[2]
diffX = x2.size()[3] - a1.size()[3]
a1 = F.pad(a1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
if self.attention:
x2 = self.attn(g=a1,x=x2)
x = torch.cat([x2, a1], dim=1)
return self.conv(x)
OutConv
Class containing the final convolutional layer used for segmenting the final image in the U-Net and the U-Net + DANN architectures.
It gives as an output the logits, with which, the classes predicted can be obtained.
Attributes
- self.in_channels: (int) Number of channels that the module receives.
- self.out_channels: (int) Number of channels that will be obtained with the convolution performed. This should be the number of classes that will be predicted in the image.
Methods
- forward: Function to perform the forward step of the group of PyTorch layers.
Source code
class OutConv(nn.Module):
"""
Final convolutional layer used for segmentation purposes.
"""
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
x = self.conv(x)
return x
OutDisc
Class containing the fully connected layers used to discriminate if the features extracted for an image come from the source domain or the target domain.
The fully connected layer is composed of:
- A flattening layer to convert the feature maps into a unidimensional tensor.
- Three Linear fully connected layers.
- Two ReLU activation functions after the first two fully connected layers.
Attributes
- self.in_feat: (int) Number of features that enter the layer.
- self.mid_layers: (int) Number of layers
Methods
- forward: Function to perform the forward step of the group of PyTorch layers.
Source code
class OutDisc(nn.Module):
def __init__(self, in_feat, mid_layers):
super(OutDisc, self).__init__()
self.disc = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=in_feat, out_features=mid_layers, bias = False),
nn.ReLU(),
nn.Linear(in_features = mid_layers, out_features = mid_layers//2, bias = False),
nn.ReLU(),
nn.Linear(in_features = mid_layers//2, out_features = 1, bias = False)
)
def forward(self, x):
return self.disc(x)
GradReverse
Class containing the function to perform the reversal of the gradient in the discriminator part of the U-Net + DANN architecture.
It inherits all of the attributes and methods from torch.autograd.Function.
The function applied to the discriminator gradient during the backward propagation is:
The value of will determine the weight of learning of the discriminator head, during the Domain Adaptation phase.
Big shout out to CuthbertCai who had already implemented the gradient reversal function in PyTorch, which I used for my implementation of the U-Net + DANN.
Overview
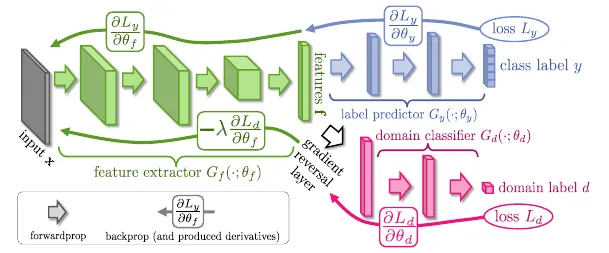
Attributes
- constant: (Float) Number indicating the weight of learning done by the discriminator head in U-Net + DANN.
Methods
- forward: Function to perform the forward step.
- backward: Function to perform the backward propagation.
- grad_reverse: Function to apply the gradient reversal to a PyTorch layer.
Source code
class GradReverse(torch.autograd.Function):
"""
Extension of gradient reversal layer
"""
@staticmethod
def forward(ctx, x, constant):
ctx.constant = constant
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
grad_output = grad_output.neg() * ctx.constant
return grad_output, None
def grad_reverse(x, constant):
return GradReverse.apply(x, constant)
Attention_block
Class containing the implementation of the attention gates used in the attention U-Net. Atention gates help the network focus on targeted regions by supressing feature activations in irrelevant regions, which reduces the number of redundant features brought across.
Big shout out to LeeJunHyun whose implementation of the attention gates inspired the ones used in my implementation.
Overview
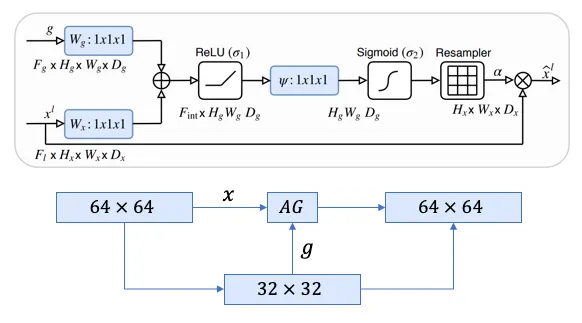
Attributes
-
self.F_g: (int) Number of feature maps entering from the gated signal.
-
self.F_l: (int) Number of feature maps entering from the input layer.
-
self.F_int: (int) Number of feature maps resulting after The convolution on the gated signal W_g and the convolution on the input layer W_x.
-
self.W_g (torch.nn.Sequential) Sequential layer with one convolution and one batch normalization layer that will be applied to the gated signal.
-
self.W_x (torch.nn.Sequential) Sequential layer with one convolution and one batch normalization that will be applied to the input layer.
-
self.psi (torch.nn.Sequential) Sequential layer with one convolution, one batch normalization and one sigmoid activation function applied to the result of the addition of the resulting feature maps coming from the gated signal and the input layer.
-
self.relu (torch.nn.ReLU) ReLU activation function.
Methods
- forward: Function to perform the forward step of the group of PyTorch layers.
Source code
class Attention_block(nn.Module):
def __init__(self,F_g,F_l,F_int):
super(Attention_block,self).__init__()
self.F_g = F_g
self.F_l = F_l
self.F_int = F_int
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self,g,x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.relu(g1+x1)
psi = self.psi(psi)
return x*psi